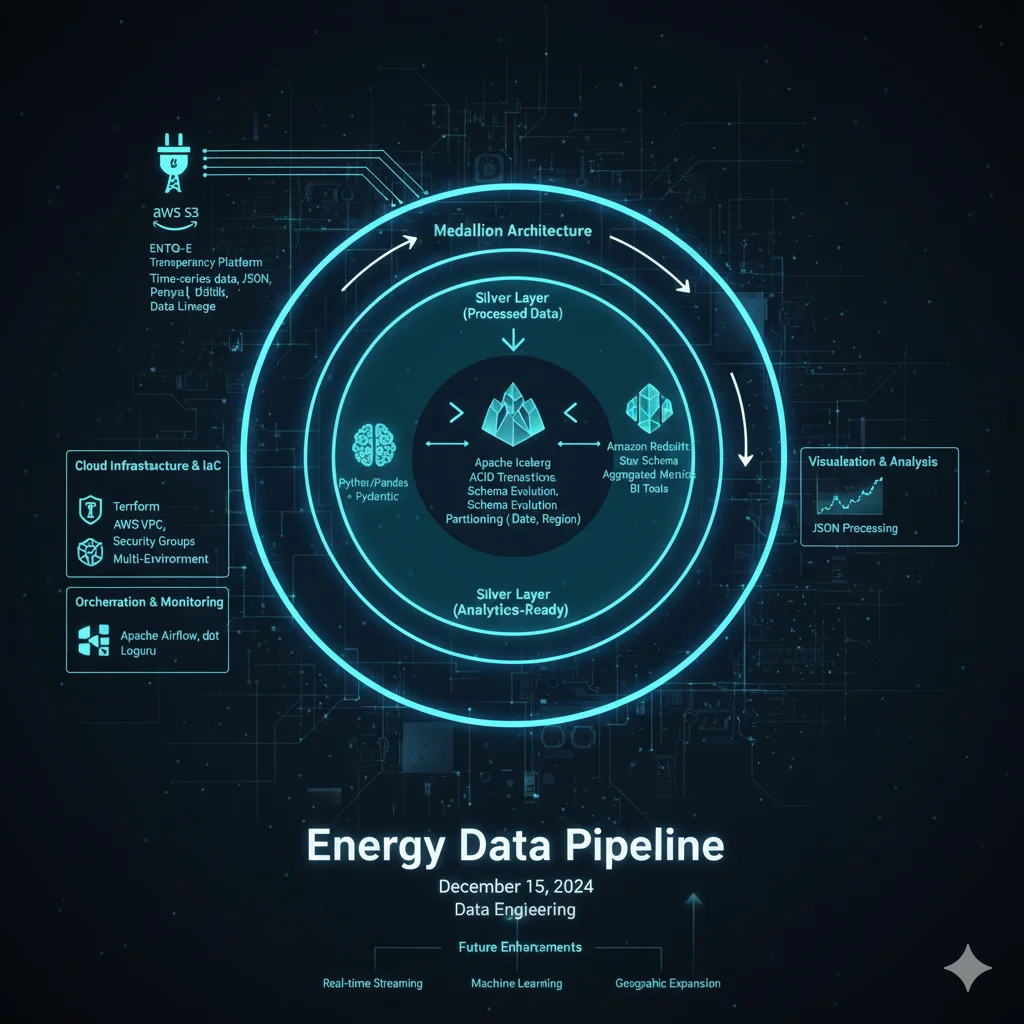
A modern data engineering solution that processes real-world electricity grid data from the ENTSO-E (European Network of Transmission System Operators for Electricity) platform. The project implements a comprehensive data lakehouse architecture using cloud-native technologies and follows industry best practices for scalable data processing.
Project Objective
The pipeline processes energy grid data (electricity consumption and generation) to support asset management and market data workflows similar to those used by utility companies and energy traders.
System Architecture
The solution implements a medallion architecture (Bronze-Silver-Gold) following modern data engineering patterns:
Bronze Layer (Raw Data)
- AWS S3 stores raw ENTSO-E meter data
- Preserves original data format and structure
- Maintains complete data lineage
Silver Layer (Processed Data)
- Apache Iceberg tables for data cleaning and transformation
- ACID transactions and schema evolution support
- Optimized partitioning by date and region
Gold Layer (Analytics-Ready)
- Amazon Redshift with star schema modeling
- Aggregated metrics for business intelligence
- Performance-optimized for analytical queries
Technology Stack
Cloud Infrastructure & IaC
- AWS Services: S3, Redshift, VPC, Security Groups
- Terraform: Infrastructure as Code for reproducible deployments
- Multi-environment: Automated resource provisioning for dev/test/prod
Data Processing & Validation
- Python: Core processing language with pandas for data manipulation
- Pydantic: Schema validation and data quality enforcement
- Apache Iceberg: Modern table format with ACID transactions
Orchestration & Monitoring
- Apache Airflow: Workflow orchestration and scheduling
- dbt (Data Build Tool): SQL-based transformations in Redshift
- Loguru: Structured logging and monitoring
Visualization & Analysis
- Matplotlib: Data visualization and exploratory analysis
- JSON Processing: Structured data handling and transformation
Data Source & Processing
ENTSO-E Transparency Platform
- Real European electricity grid data from multiple countries
- Time-series data with hourly electricity load and generation measurements
- Approximately 1,000 rows covering 1-2 months of operational data from Finland
Data Characteristics
- High-frequency time series with consistent intervals
- Multiple data types including consumption, generation, and grid balancing
- Real-world data quality challenges requiring robust validation
Implementation Features
Data Validation & Quality
- Custom Pydantic models for ENTSO-E data schema validation
- Type checking and domain-specific validation (e.g., positive load values)
- Graceful error handling with detailed logging
- Data quality metrics and monitoring
Infrastructure & Scalability
- Multi-environment support with automated provisioning
- Secure networking with VPC and security groups
- Auto-scaling Redshift clusters for variable workloads
- Cost-optimized storage with S3 lifecycle policies
Engineering Best Practices
- Infrastructure as Code with Terraform modules
- Modular code architecture with clear separation of concerns
- Comprehensive logging and error monitoring
- Environment-specific configurations and secrets management
Project Structure
energy-data-pipeline/
├── terraform/ # Infrastructure provisioning and management
├── scripts/ # Data processing and validation modules
├── dbt/ # SQL transformations for Redshift
├── airflow/ # Workflow orchestration and DAGs
├── data/ # Sample ENTSO-E datasets for testing
└── requirements.txt # Python dependencies and versions
Technical Architecture
Core Technologies
The pipeline leverages modern data engineering tools and cloud services:
- Data Storage: S3 for raw data, Iceberg for processed data, Redshift for analytics
- Processing: Python with pandas for data transformation and Pydantic for validation
- Orchestration: Airflow for workflow management and scheduling
- Infrastructure: Terraform for cloud resource provisioning and management
- Monitoring: Loguru for structured logging and observability
Business Applications
Energy Market Analysis
- Real-time processing supports trading desk operations and market analysis
- Historical data aggregation enables demand forecasting and capacity planning
- Grid balancing metrics support operational decision making
Scalable Operations
- Pipeline can handle enterprise-level energy data volumes
- Efficient data partitioning optimizes query performance and costs
- Multi-region architecture supports global energy companies
Industry Compliance
- Data lineage tracking meets regulatory requirements
- Audit trails provide transparency for market reporting
- Security controls align with energy sector standards
Technical Implementation Details
Data Pipeline Architecture
The pipeline follows a three-tier medallion architecture:
Bronze Layer Implementation
- Raw ENTSO-E data ingested via REST API calls
- Data stored as JSON and Parquet formats in S3
- Minimal transformation to preserve data lineage and original structure
- Automated backup and versioning with S3 lifecycle management
Silver Layer Processing
- Pydantic models enforce data schema and quality validation
- Data cleansing removes duplicates and handles missing values
- Apache Iceberg provides ACID transactions and schema evolution
- Partitioning by date and region optimizes query performance
Gold Layer Analytics
- Star schema implementation in Amazon Redshift
- Pre-aggregated metrics reduce query latency
- Materialized views provide fast access to common analytical queries
- Integration with BI tools for business reporting
Infrastructure Management
Terraform modules provide comprehensive cloud resource management:
- Networking: VPC configuration with private subnets and security groups
- Storage: S3 buckets with encryption, versioning, and lifecycle policies
- Compute: Redshift clusters with automated backup and monitoring
- Security: IAM roles and policies implementing least privilege access
- Monitoring: CloudWatch integration for performance and cost tracking
Data Quality & Operations
- Schema Evolution: Apache Iceberg handles table schema changes without downtime
- Data Validation: Multi-level validation from ingestion through analytics
- Observability: Structured logging provides detailed pipeline monitoring
- Alerting: Airflow monitoring with configurable notification channels
- Recovery: Automated retry mechanisms and data backfill capabilities
Performance & Optimization
Query Performance
- Partitioning Strategy: Data partitioned by date and geographic region
- Compression: Columnar storage with optimal compression algorithms
- Indexing: Strategic indexes on frequently queried columns
- Caching: Query result caching reduces repeated computation costs
Cost Optimization
- Resource Scaling: Auto-scaling based on workload patterns
- Storage Tiering: Automated data lifecycle management across storage classes
- Compute Scheduling: Workload scheduling during off-peak hours
- Monitoring: Cost tracking and alerting for budget management
Future Enhancements
- Real-time Streaming: Integration with Kafka/Kinesis for live data processing
- Machine Learning: Demand forecasting models using historical patterns
- Geographic Expansion: Multi-region deployment for global energy markets
- Advanced Analytics: Time-series forecasting and anomaly detection