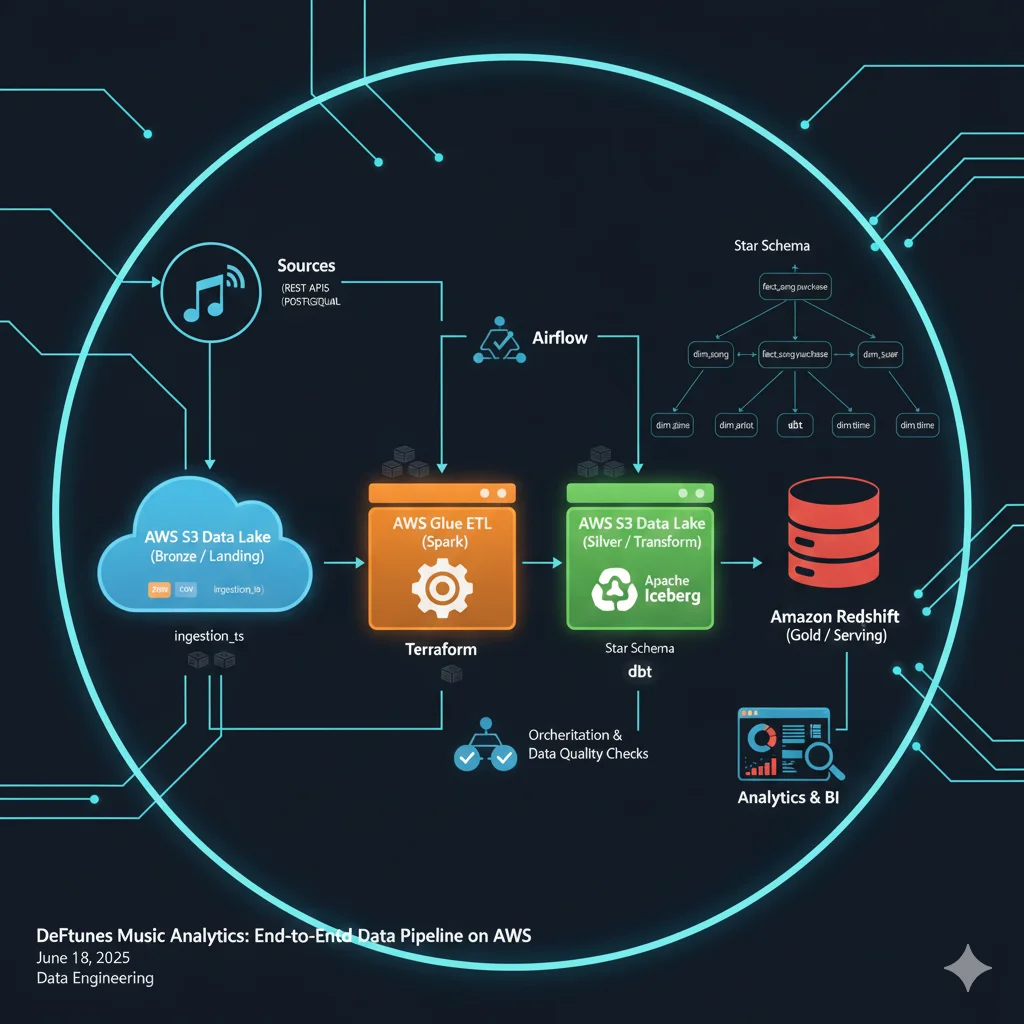
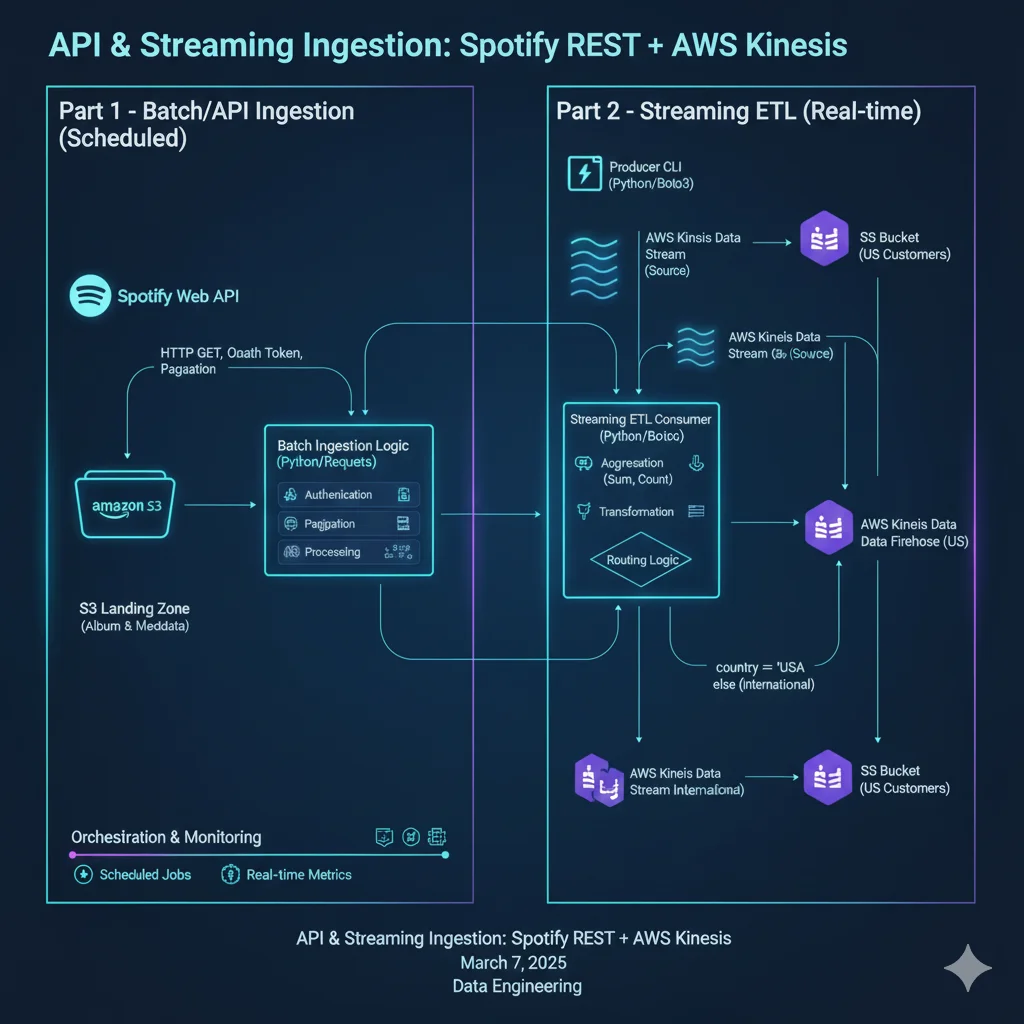
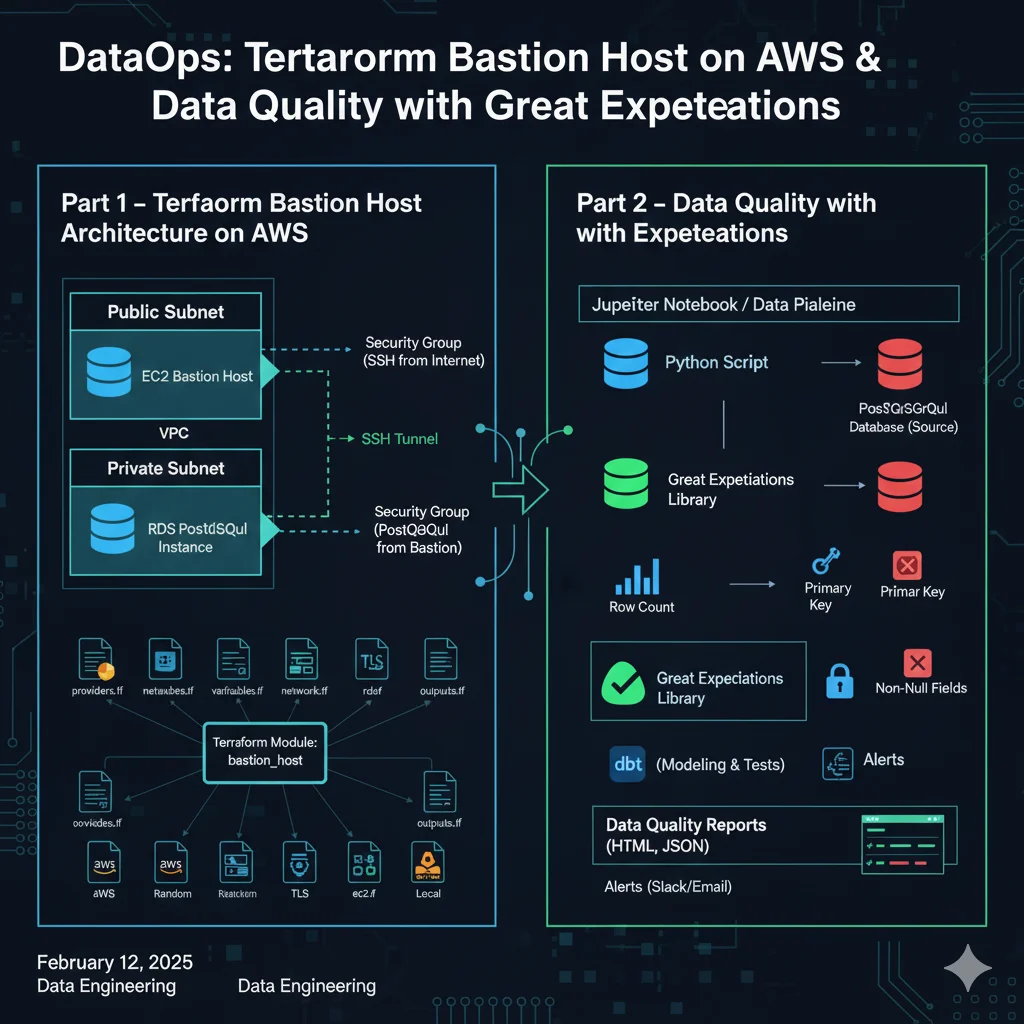
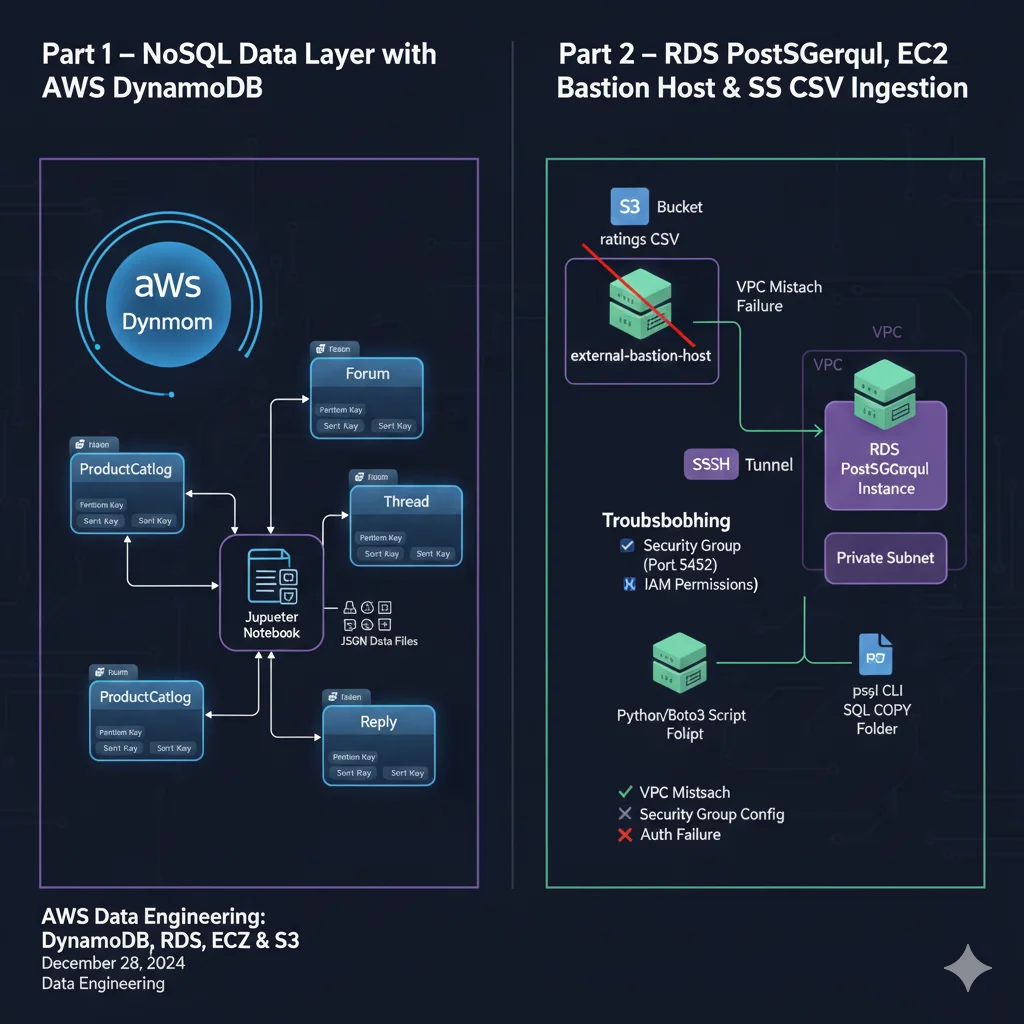
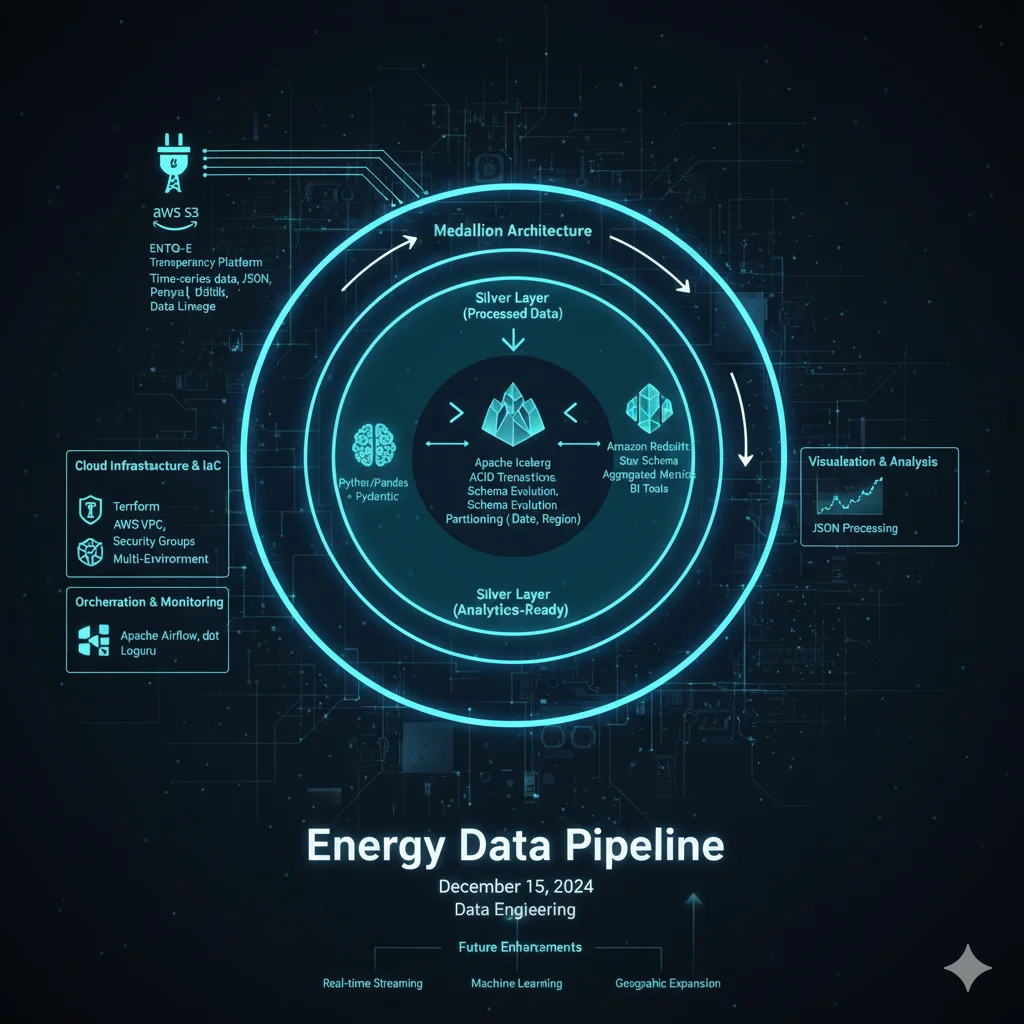
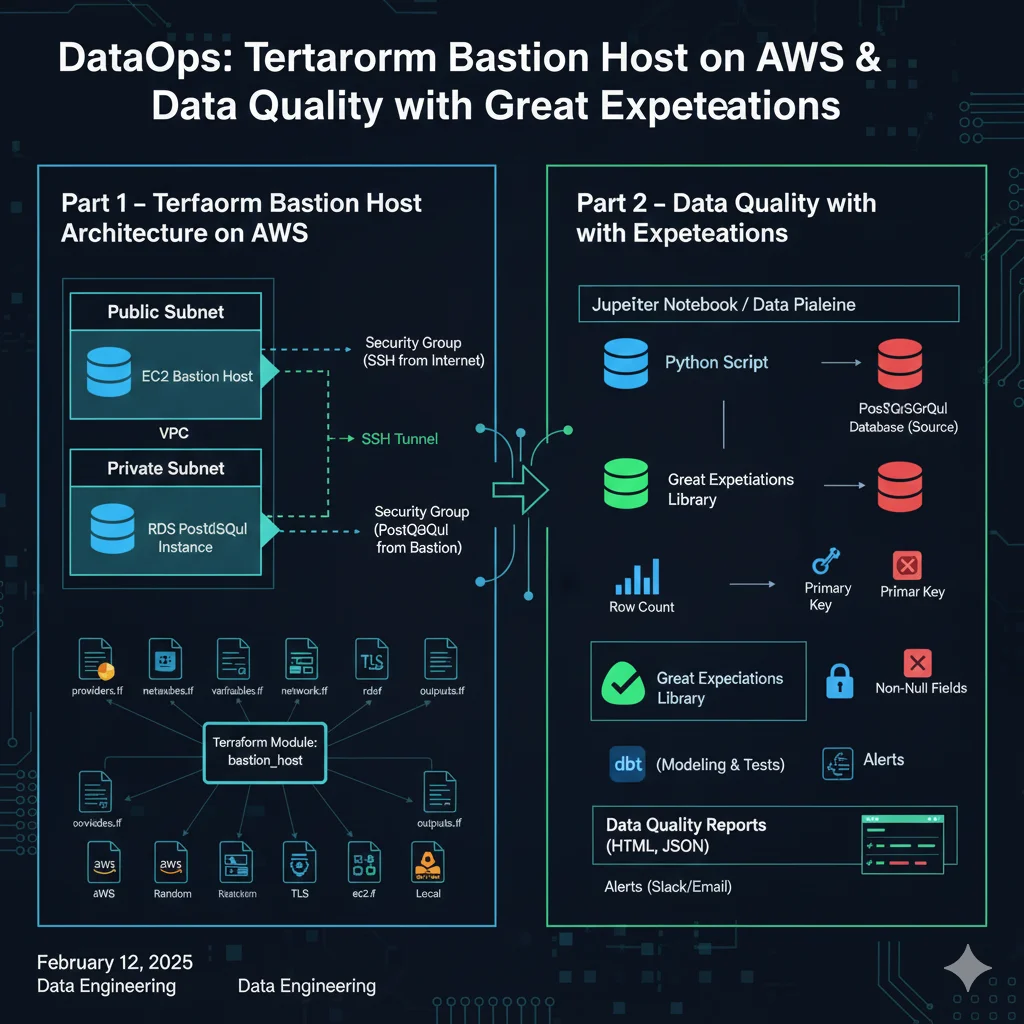
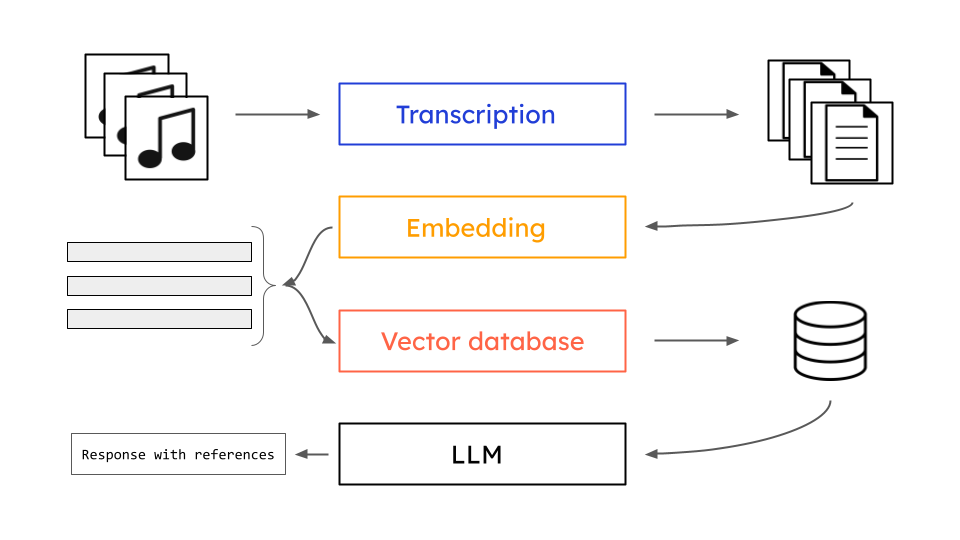
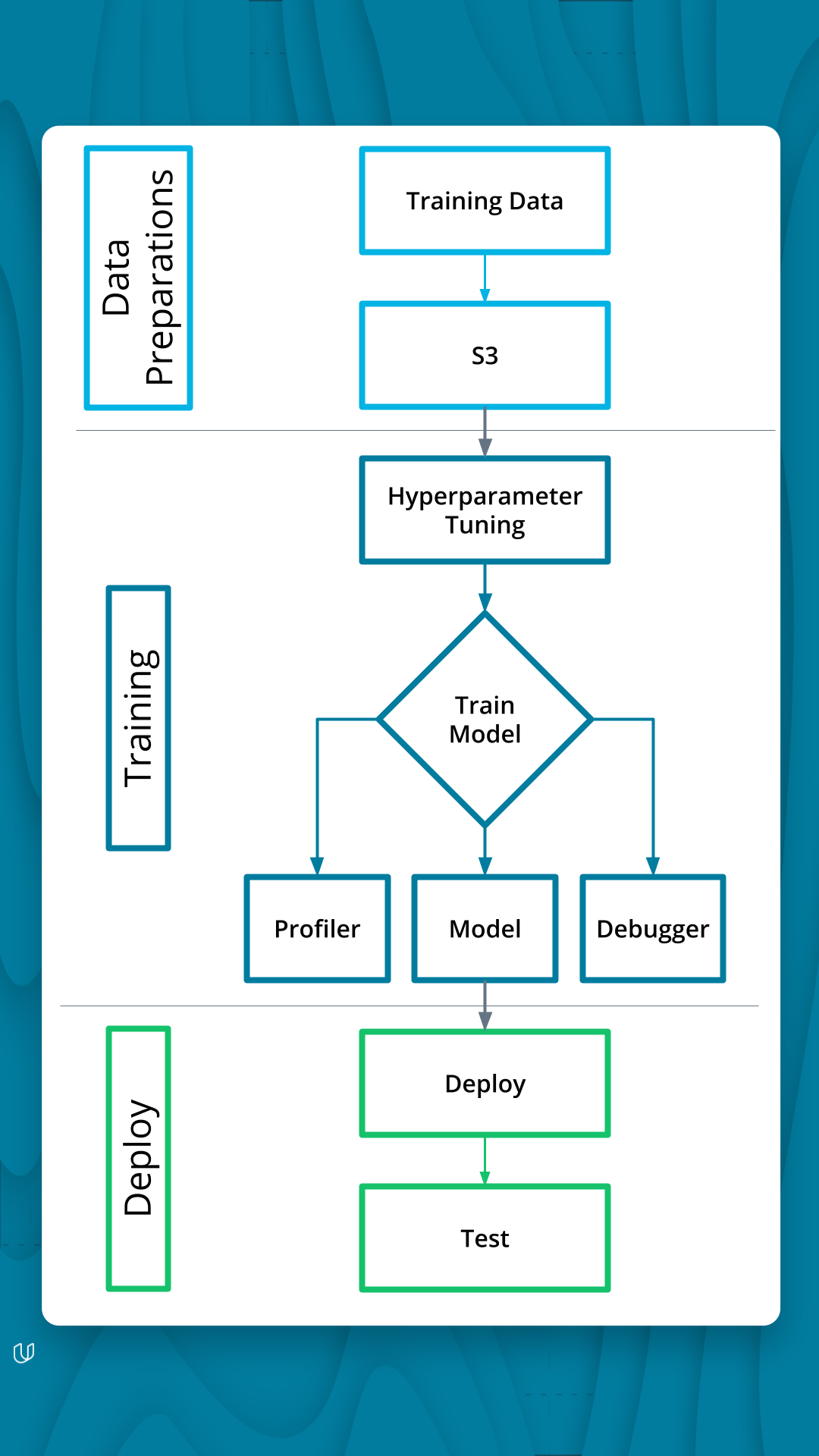
Detoxifying FLAN-T5 with RLHF (PPO + Hate-Speech Reward Model)
Fine-tuned an instruction-tuned FLAN-T5 summarization model with Reinforcement Learning from Human Feedback (RLHF) using PPO and a hate-speech reward model to reduce toxicity in generated dialogue summaries.
RLHFPPOFLAN-T5Transformers+1