Business Context
DeFtunes is a subscription-based music streaming company that added a new feature: users can now purchase and download songs.
Analytics stakeholders want to understand:
- How purchases evolve over time
- Which songs and artists drive revenue
- How purchases vary by user attributes (e.g. location, timezone)
The project delivers an end-to-end data pipeline that makes this purchase data available in an analytics-ready schema with historical raw retention, daily updates, and automated data-quality checks.
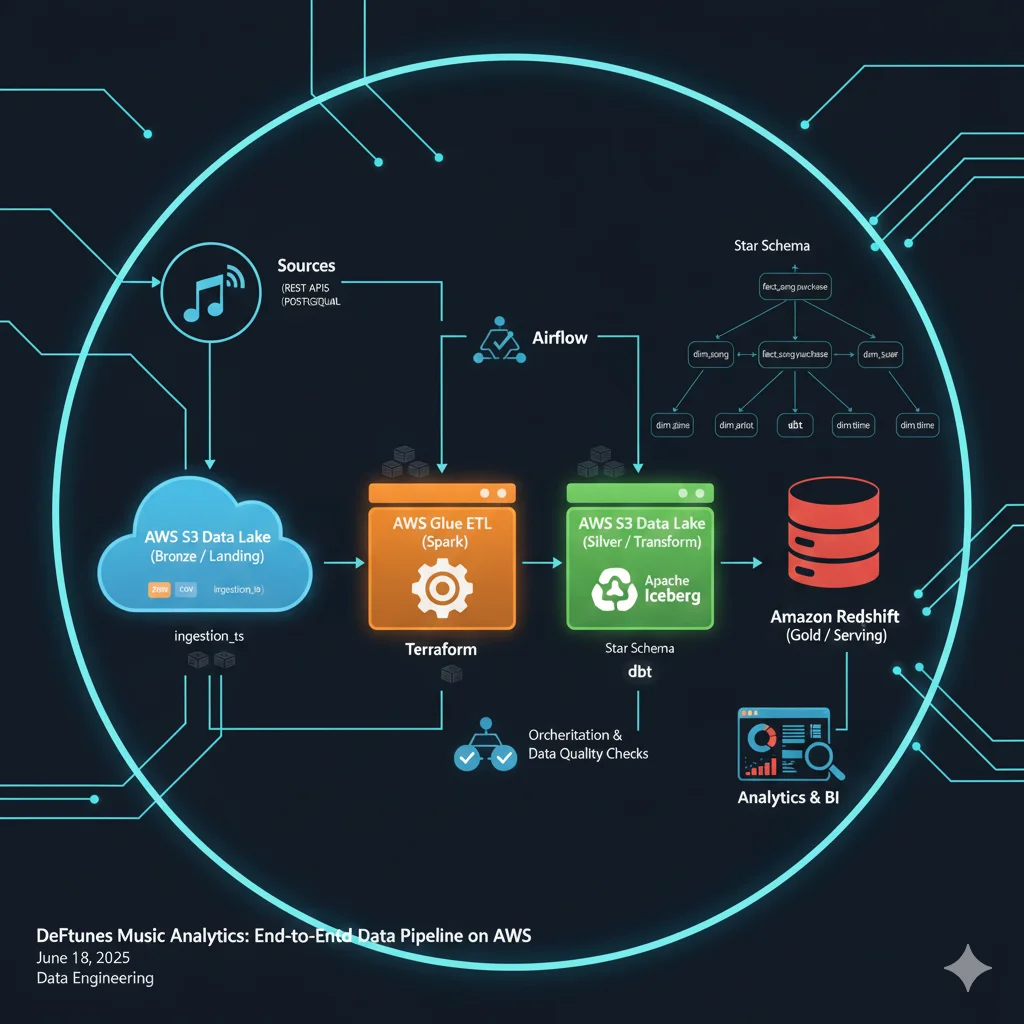
High-Level Architecture
The solution follows a medallion architecture on AWS:
- Bronze / Landing zone (S3) – raw data from APIs and PostgreSQL, stored with ingestion timestamps.
- Silver / Transform zone (S3 Iceberg) – curated, schema-enforced tables with lineage metadata.
- Gold / Serving zone (Redshift) – star-schema model optimized for analytical queries.
Key services:
- AWS S3 – central data lake (landing + transform zones)
- AWS Glue ETL (Spark) – extraction and transformation jobs
- Apache Iceberg – table format for transform-zone datasets
- Amazon Redshift + Redshift Spectrum – data warehouse & external table access
- PostgreSQL – source system for song catalog
- Custom REST API – source system for sessions & users
- Terraform – infrastructure-as-code for Glue jobs, S3 layout, Redshift, catalogs
- dbt – modeling star schema inside Redshift
- Airflow – orchestration of daily pipeline and data-quality checks
Data Sources
-
Sessions API endpoint
- JSON response containing:
session_id,user_id- Array of purchased items with song info, artist info, price, and like status.
- Represents transactional purchase sessions over a time window.
- JSON response containing:
-
Users API endpoint
- JSON response with:
- First/last name
- Location, timezone
- Subscription start date
- Used to build the user dimension and enrich sessions.
- JSON response with:
-
PostgreSQL “songs” table
- Under
deftunesschema. - Contains track ID, title, release, album, artist details, and release year.
- Used as the source for song and artist dimensions.
- Under
Data Modeling – Star Schema in Redshift
Designed a star schema with the atomic grain: a single song purchase item within a session.
Fact table – fact_song_purchase
Each row represents one purchased item:
-
Keys
fact_key(surrogate key)session_idsong_idsong_key(FK →dim_song)artist_key(FK →dim_artist)user_key(FK →dim_user)session_start_time(FK →dim_time)
-
Measures
price_usdliked(boolean)liked_since(timestamp when the user liked the song)
Dimension tables
-
dim_song- Song ID, title, album, release year
- Genre/other track-level attributes
-
dim_artist- Artist ID, name, country, other metadata
-
dim_user- User ID, first/last name
- Location (city, country)
- Timezone
- Subscription date
-
dim_time- Purchase timestamp → date, hour, day of week, month, quarter, year
The model is built and maintained with dbt models and macros, enabling future extension and documentation.
Bronze Layer – Ingestion & Landing Zone (S3)
Raw data is ingested into S3 using AWS Glue ETL jobs defined with Terraform:
-
Glue job:
extract_users_api- Calls the
usersAPI endpoint. - Writes raw JSON to:
s3://deftunes-lake/landing/users_ingestion_ts=<timestamp>/users.json
- Calls the
-
Glue job:
extract_sessions_api- Calls the
sessionsAPI endpoint. - Writes raw JSON to:
s3://deftunes-lake/landing/sessions_ingestion_ts=<timestamp>/sessions.json
- Calls the
-
Glue job:
extract_songs_postgres- Uses PostgreSQL JDBC connection to read
deftunes.songs. - Writes CSV to:
s3://deftunes-lake/landing/songs_ingestion_ts=<timestamp>/songs.csv
- Uses PostgreSQL JDBC connection to read
Each file path includes an ingestion timestamp partition to preserve history and support reprocessing.
Silver Layer – Transform Zone with Iceberg
The raw datasets are transformed and enriched with Glue/Spark and stored as Iceberg tables.
Transform job: Users & Sessions JSON → Iceberg
transform_json Glue job:
- Reads raw users JSON into a Spark DataFrame.
- Location enrichment from a single
locationfield into:latitudelongitudeplace_namecountry_codetime_zone
- Adds lineage columns:
ingestion_ts(when data landed)processing_ts(when transform ran)
- Writes to Iceberg at:
s3://deftunes-lake/transform/users/
For sessions:
- Reads raw sessions JSON into a DataFrame.
- Explodes the
session_itemsarray so each purchased item becomes its own row. - Adds the same lineage columns (
ingestion_ts,processing_ts). - Writes to Iceberg at:
s3://deftunes-lake/transform/sessions/
Transform job: Songs CSV → Iceberg
transform_songs Glue job:
- Reads
songs.csvfrom the landing zone. - Performs schema enforcement (types, required fields).
- Adds lineage columns:
ingestion_tssource_db_name(e.g.deftunes_postgres)
- Writes as Iceberg to:
s3://deftunes-lake/transform/songs/
Glue Data Catalog & Transform DB
- Creates a Glue database catalog:
transform_db. - Registers Iceberg tables:
transform_db.userstransform_db.sessionstransform_db.songs
These tables are then queryable via Redshift Spectrum as external tables.
Gold Layer – Serving Zone in Redshift (with dbt)
Using Terraform, the project configures:
- Redshift provider with cluster credentials.
- Schemas:
analytics_internal– internal schema storing dbt-managed star-schema tables.analytics_external– external schema pointing totransform_dbin Glue (for Spectrum).
An existing IAM role is attached to allow Redshift Spectrum to read from the S3 transform zone.
Modeling with dbt
- dbt models use external transform tables as sources:
source('transform_db', 'sessions'),source('transform_db', 'users'),source('transform_db', 'songs').
- Build
dim_*andfact_song_purchasetables insideanalytics_internal. - Add:
- Incremental strategies to support daily updates.
- Tests for primary/foreign keys and non-null critical fields.
- Documentation blocks that describe each model and column.
Orchestration & Data Quality with Airflow
Airflow orchestrates the daily pipeline:
-
Ingestion DAG
- Triggers Glue extract jobs for:
usersAPIsessionsAPI- PostgreSQL
songstable
- Waits for successful completion.
- Triggers Glue extract jobs for:
-
Transform DAG
- Runs Glue transform jobs for JSON and songs CSV.
- Updates Iceberg tables in
transform_db.
-
Modeling DAG
- Executes dbt run/test for the star schema in Redshift.
- Refreshes analytical views.
-
Data-quality checks
- Airflow tasks and dbt tests validate:
- Row counts above minimum thresholds.
- No duplicate natural keys in dimensions.
- No null foreign keys in the fact table.
- Reasonable ranges for prices and timestamps.
- Airflow tasks and dbt tests validate:
Alerts can be configured for failures or data-quality test violations.
Analytics & Usage
With the star schema in place, analysts can easily answer questions such as:
- Revenue and purchase counts by song, artist, and time.
- Top performing artists by country or city.
- Cohort analysis of users by subscription date and purchase behavior.
- Impact of likes (
liked,liked_since) on purchasing.
Views and BI dashboards can be built directly on top of Redshift, using the fact and dimension tables.
Key Skills
- Cloud & Infra: AWS S3, Glue, Redshift, Redshift Spectrum, Glue Data Catalog, IAM
- Table Format: Apache Iceberg for transform-zone tables
- Orchestration & IaC: Airflow, Terraform
- Modeling: Star schema design, dbt models & tests, medallion architecture
- Sources & Ingestion: REST APIs, PostgreSQL, JSON, CSV
- Data Engineering: lineage metadata, schema enforcement, daily incremental loads, data quality