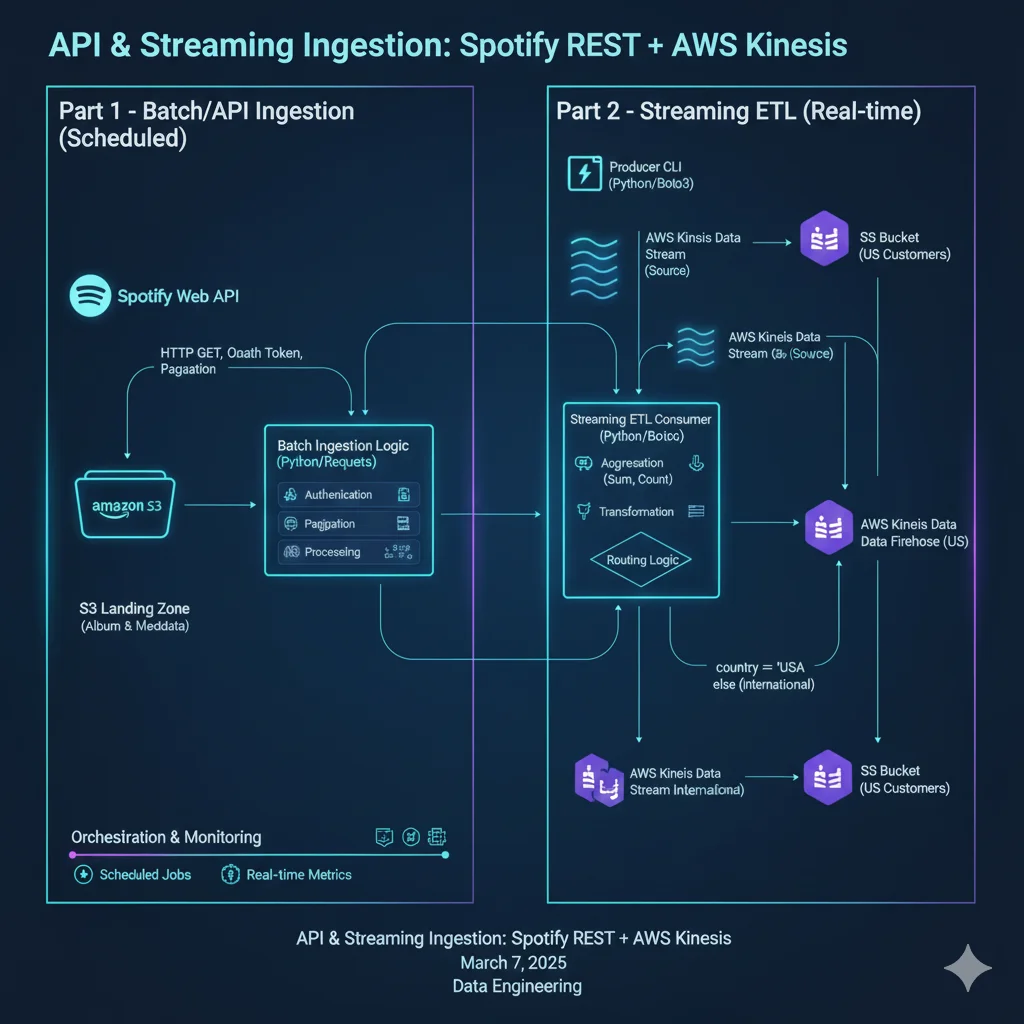
Overview
This project explores two complementary ingestion patterns:
- Batch/API ingestion from the Spotify Web API.
- Streaming ETL on AWS using Kinesis Data Streams, Kinesis Data Firehose, and S3.
The goal is to practice real-world concerns around authentication, pagination, routing, and in-flight transformations for both REST and event-stream sources.
Part 1 – Batch/API Ingestion with Spotify Web API
I built a small batch ingestion workflow that connects to the Spotify Web API to fetch metadata about new album releases and their tracks.
Key features
-
API authentication
- Registered a Spotify developer application.
- Obtained Client ID and Client Secret and stored them in environment variables.
- Implemented a
getToken(client_id, client_secret)function that:- Calls Spotify’s authorization endpoint.
- Returns an access token, token type, and expiry.
- Handled token expiry by regenerating a new token when needed.
-
HTTP requests with Python
- Used the
requestslibrary to perform GET requests against Spotify endpoints such as:Get New ReleasesGet Album Tracks
- Built an
get_auth_header(access_token)helper that returns the correctAuthorization: Bearer <token>header.
- Used the
-
Pagination
- Implemented helper functions that:
- Use
offsetandlimitquery parameters to fetch albums in chunks. - Alternatively follow the
nextfield from the API response to iterate through pages.
- Use
- Collected all pages to build a complete list of new album releases (100+ items).
- Implemented helper functions that:
-
Batch ingestion logic
- First paginated call:
- Fetch all new album releases and extract their album IDs.
- Second paginated call:
- For each album ID, call
Get Album Tracksto retrieve full track metadata.
- For each album ID, call
- Encapsulated this logic in reusable Python functions (
endpoints.py,authentication.py, and amaindriver script).
- First paginated call:
Concepts & skills
- REST APIs, HTTP verbs (
GET,POST,PUT,DELETE) and status codes (200,400,404, etc.). - OAuth-style token-based authorization and token rotation.
- Pagination patterns (
offset/limitvsnextURL). - Working with JSON responses and mapping them to Python dicts and lists for further processing.
- Designing API-based batch ingestion that can later feed a warehouse or data lake.
Part 2 – Streaming ETL with AWS Kinesis, Firehose & S3
The second part of the project focuses on streaming ingestion and in-flight transformations for a simple e-commerce recommender scenario.
Scenario
- Source system: a Kinesis Data Stream with user activity events.
- Each event is a JSON record with fields such as:
session_id,customer_number,city,countrybrowsing_historywith product IDs, quantities, and cart flags.
- Target: separate downstream pipelines for US and international customers, each landing into its own S3 bucket via Firehose.
Components
-
Producer CLI (Python + Boto3)
- Simple producer script that:
- Accepts the Kinesis stream name and a JSON record as arguments.
- Uses
boto3andput_recordto write events into the stream.
- Simple producer script that:
-
Consumer CLI (Python + Boto3)
- Consumer script that:
- Accepts the stream name (and later destination stream names) as arguments.
- Iterates through all shards with
get_shard_iterator/get_records. - Prints which record was read from which shard and position (for observability).
- Consumer script that:
-
Streaming ETL consumer
- Extended the consumer to perform real transformations and routing:
- Reads events from a source Kinesis Data Stream.
- Computes three aggregated fields per session:
overall_product_quantity– sum of all product quantities inbrowsing_history.overall_in_shopping_cart– sum of quantities for items flagged as in the shopping cart.total_different_products– number of distinct products in the browsing history.
- Routes the transformed record to one of two destination Kinesis Data Streams:
- US stream for
country == "USA". - International stream for all other countries.
- US stream for
- Destination streams are each connected to Kinesis Data Firehose instances which automatically deliver data into separate S3 buckets.
- Extended the consumer to perform real transformations and routing:
-
Infrastructure with Boto3
- Used Python + Boto3 to create:
- Kinesis Data Streams (source and two destinations).
- Kinesis Data Firehose delivery streams.
- S3 buckets for US and international customers.
- Used Python + Boto3 to create:
Streaming flow
- Producer writes user session events into the source Kinesis stream.
- Streaming ETL consumer:
- Pulls records shard by shard.
- Enriches records with aggregate fields.
- Routes records into US or International Kinesis streams based on
country.
- Kinesis Data Firehose:
- Continuously delivers records from each destination stream into its S3 bucket.
- S3 serves as durable storage and the entry point for downstream recommendation engines.
Concepts & skills
- Event streaming with AWS Kinesis Data Streams (shards, records, iterators).
- Building producer and consumer applications with Python + Boto3.
- In-flight transformations in streaming pipelines.
- Routing logic for multi-tenant/multi-region processing.
- Integrating Kinesis Data Firehose with S3 for durable storage.
- Designing streaming ingestion for recommender systems that need different models per segment (US vs international).
Design Considerations for Ingestion
This project also reflects several design considerations for ingestion tools and pipelines:
- Data type & structure: JSON events and API responses with nested fields.
- Data volume & velocity: streams of online activity events vs batched API calls of album metadata.
- Latency requirements: near real-time processing for streaming events; scheduled batch jobs for Spotify API.
- Data quality: handling missing or inconsistent fields in JSON records and preparing them for downstream models.
- Schema changes: APIs and event schemas may evolve; code is structured to make adding new fields straightforward.
- Reliability & durability: Kinesis + S3 provide durable storage; routing logic avoids data loss even if one downstream path is slow.
Key Skills
APIs & Batch Ingestion: Spotify Web API, REST, HTTP, OAuth-style auth, pagination, JSON
Streaming & Cloud: AWS Kinesis Data Streams, Kinesis Data Firehose, S3
Programming: Python, Requests, Boto3, CLI scripts, JSON processing
Data Engineering: batch vs streaming design, in-flight transformations, routing, ingestion reliability