Stack used
- AssemblyAI: https://www.assemblyai.com/ for transcription
- LangChain: https://www.langchain.com/
- Hugging Face: https://huggingface.co/ for embeddings
- Chromadb: https://www.trychroma.com/ as a vector database
- OpenAI: https://openai.com/ language model
APIs:
- AssemblyAI API key: https://www.assemblyai.com/dashboard/…
- OpenAI API key: https://openai.com/blog/openai-api
Introduction
Retrieval Augmented Generation (RAG) is a method to augment the relevance and transparency of Large Language Model (LLM) responses. In this approach, the LLM query retrieves relevant documents from a database and passes these into the LLM as additional context. RAG therefore helps improve the relevancy of responses by including pertinent information in the context, and also improves transparency by letting the LLM reference and cite source documents
RAG stands for “Retrieval-Augmented Generation.” It is a language model architecture that combines retrieval-based methods with generation-based methods for question answering tasks. RAG uses a retriever component to retrieve relevant passages or documents from a large corpus, and then a generator component to generate the answer based on the retrieved information. This approach allows RAG to leverage both the benefits of retrieval-based models (retrieving relevant information) and generation-based models (generating coherent and contextually appropriate answers).
Background
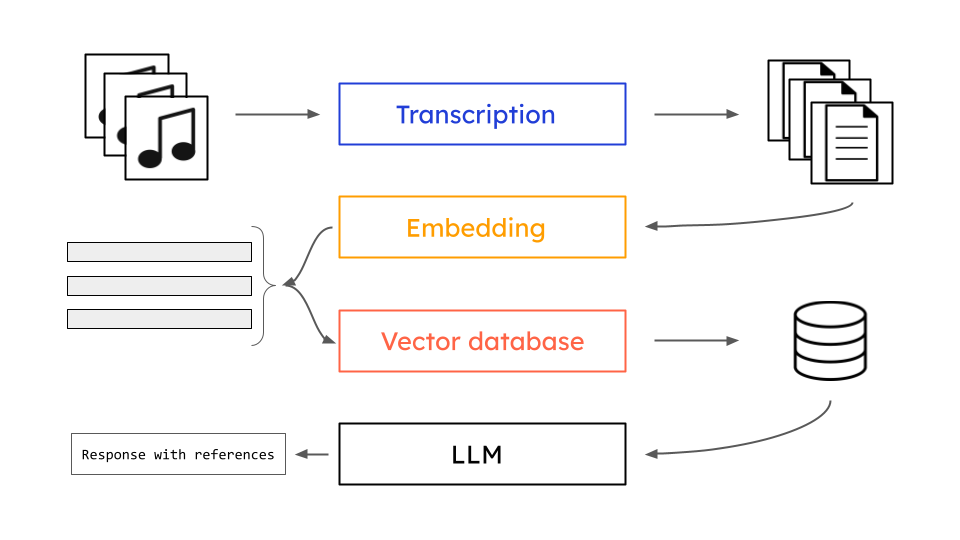
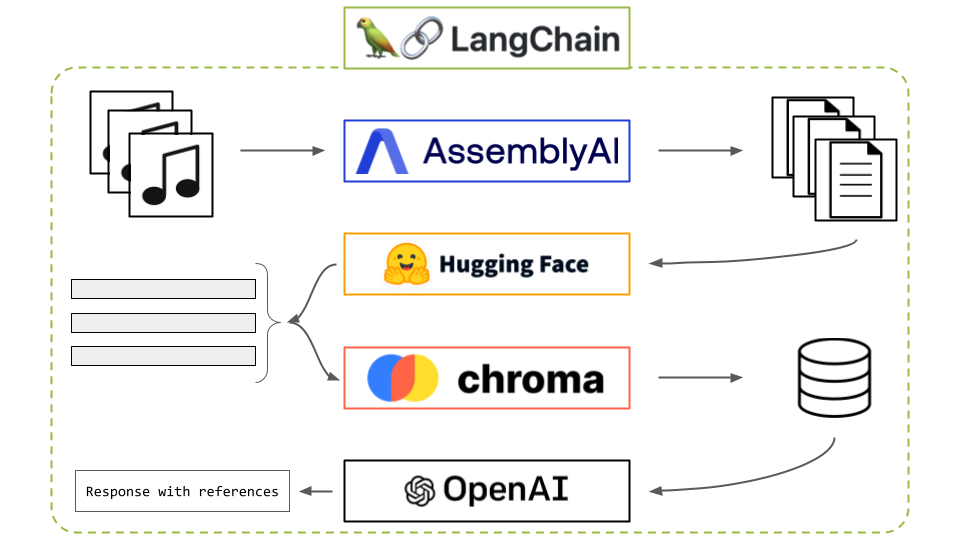
In this project, Retrieval Augmented Generation(RAG) with audio data by leveraging AssemblyAI’s document loader for LangChain, a popular framework that provides building blocks for LLM-based applications, using Chroma as the vector database to store our document embeddings.
Imports and environment variables
from dotenv import load_dotenv
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import AssemblyAIAudioTranscriptLoader
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
load_dotenv()
Project Pipeline
- AssemblyAI for transcribing audio into text since LLMs can only process textual data
- Hugging Face for document embeding, these are numerical representation of the documents
- Chromadb for storing the embedings will make easy to make similarity search to extact document which are relevant to our quary
- OpenAI for document retriaval
- These pieces are all tied together by langchain
Dataset
The audio files which are used in this project are romete audio files which we access through the URLs. These are langchain webners series in youtube.
Loading the documents
The AssemblyAIAudioTranscriptLoader allows us to load audio files, local or remote, into LangChain applications.
URLs = [
"https://storage.googleapis.com/aai-web-samples/langchain_agents_webinar.opus",
"https://storage.googleapis.com/aai-web-samples/langchain_document_qna_webinar.opus",
"https://storage.googleapis.com/aai-web-samples/langchain_retrieval_webinar.opus"
]
def create_docs(urls_list):
l = []
for url in urls_list:
print(f'Transcribing {url}')
l.append(AssemblyAIAudioTranscriptLoader(file_path=url).load()[0])
return l
docs = create_docs(URLs)
Document splitting and metadata
We sprit the text so as to select the relevant chunk of the text and are non overlaping pieces using RecursiveCharacterTextSplitter.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(docs)
We make sure its the metadata from the url we have given
for text in texts:
text.metadata = {"audio_url": text.metadata["audio_url"]}
Methodology
Embed texts
Here we use the hugging face to embed our texts and store the embeddings in chromadb
def make_embedder():
model_name = "sentence-transformers/all-mpnet-base-v2"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}
return HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
hf = make_embedder()
db = Chroma.from_documents(texts, hf)
Creating the Q&A chain
The question and answer chain pulls all the pieces together by specifying the model we are using which is gpt3.5 turbo with a temperature of 0. The we return the source documents with ranking.
def make_qa_chain():
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
return RetrievalQA.from_chain_type(
llm,
retriever=db.as_retriever(search_type="mmr", search_kwargs={'fetch_k': 3}),
return_source_documents=True
)
The Q&A chain
print('\nEnter `e` to exit')
qa_chain = make_qa_chain()
while True:
q = input('enter your question: ')
if q == 'e':
break
result = qa_chain({"query": q})
print(f"Q: {result['query'].strip()}")
print(f"A: {result['result'].strip()}\n")
print("SOURCES:")
for idx, elt in enumerate(result['source_documents']):
print(f" Source {idx}:")
print(f" Filepath: {elt.metadata['audio_url']}")
print(f" Contents: {elt.page_content}")
print('\n')
Results
Transcribing files ... (may take several minutes)
Transcribing https://storage.googleapis.com/aai-web-samples/langchain_agents_webinar.opus
Transcribing https://storage.googleapis.com/aai-web-samples/langchain_document_qna_webinar.opus
Transcribing https://storage.googleapis.com/aai-web-samples/langchain_retrieval_webinar.opus
Splitting documents
Embedding texts...
enter your question: what is RAG
Q: what is RAG
A: RAG stands for "Retrieval-Augmented Generation." It is a language model architecture that combines retrieval-based methods with generation-based methods for question answering tasks. RAG uses a retriever component to retrieve relevant passages or documents from a large corpus, and then a generator component to generate the answer based on the retrieved information. This approach allows RAG to leverage both the benefits of retrieval-based models (retrieving relevant information) and generation-based models (generating coherent and contextually appropriate answers).
SOURCES:
Source 0:
Filepath: https://storage.googleapis.com/aai-web-samples/langchain_document_qna_webinar.opus
Contents: clean chunking. And so actually, I don't even care about chunking correctly. So Paper QA has its own parser that just cuts at the character level. No thought or work on getting the chunks into nice orders. Doesn't seem to matter. And just I know there's going be to a whole bunch of discussion. So I just want to show like a little demo is that the latest thing though has been getting the papers, right? So the last thing I did was I took Langchain and made an agent that will basically have access to these different steps of getting context, doing keyword searches over papers, choosing which papers to read. And I put it together into an agent that basically has choose papers, gather evidence and the way it searches papers is from Archive Bio, archive scholar and it looks at citations. So here's a question of like why do birds flock? And it goes and it does a keyword search of papers. It gets a few papers out and the agent has to use the paper QA, final answer. And it generates an answer.
Source 1:
Filepath: https://storage.googleapis.com/aai-web-samples/langchain_agents_webinar.opus
Contents: scientific research paper. And that was the output. So it's absolutely not an actual scientific research paper. But it seemed in line with what I was seeing in the market. And then the reaction continued, and I saw auto GPT, and I thought, well, if this is out, might as well open source my code. I like simple code. So I really pared it down to what, 105 lines of code? And I took the original nickname that Jenny, gave it, baby AGI, and released it on GitHub, and it's been pretty wild. So that's the backstory. I can explain how it works. The way it works is it's actually the same way I work, which is that you have a task execution agent that just does the first task on the task list. Then at the end of a task, there's a task creation agent who says, okay, you finished this task. What other tasks should we do based on that result? And then a task prioritization agent who basically reorders the tasks and sends the first task to the task execution agent. And I designed it that way because
Source 2:
Filepath: https://storage.googleapis.com/aai-web-samples/langchain_retrieval_webinar.opus
Contents: infrastructure. So that's where something like vespa's flexibility, I think the query language joe didn't get a chance to highlight that, but it's maybe not as much as we'd like, but it's a very powerful query language that makes that I so I'm happy to take more questions about that. But I wanted to highlight sort of a kind of a bigger picture story here. So suppose that you're not working in isolation and I think a lot of the questions were talking about scenarios where you just don't have a lot of data and you can't just train your own retrievers and such and you could just use Colbert out of the box zero shot, but could you do better? And so we spent the last two to three years looking at how we can apply Colbert to new domains. So I mentioned Kobe V two already for zero shot search. But if you wanted to answer questions with language models, we've looked at Kobe QA which is this sort of pipeline for essentially very similar to Rag, but has a different supervision technique and
enter your question:
Conclusion
This project aimed on how to perform RAG on audio data with LangChain using AssemblyAI for transcription, HuggingFace for embeddings, Chroma as a vector database, and OpenAI’s GPT 3.5 as a language model